

弥合自然智能和人工智能之间差距的下一步是什么? 科学家和研究人员在答案上存在分歧。 Meta 首席人工智能科学家、2018 年图灵奖获得者 Yann LeCun 押注于自我监督学习,即无需人工标记示例即可进行训练的机器学习模型。
多年来,LeCun 一直在思考和谈论 自我监督和无监督学习 。 但随着他的研究以及人工智能和神经科学领域的进步,他的愿景已经集中在几个有前途的概念和趋势上。
在 Meta AI 最近举办的 可能途径 人类级别 AI 的 、仍然存在的挑战以及 AI 进步的影响。
世界模型是高效学习的核心
的 深度学习 是需要大量训练数据并且在处理新情况时缺乏鲁棒性。 后者被称为“分布外泛化”或对“边缘情况”的敏感性。
这些是人类和动物在生命早期就学会解决的问题。 你不需要开车掉下悬崖就知道你的车会掉下来撞车。 要知道,当一个物体遮挡另一个物体时,后者即使看不到也依然存在。 你知道,如果你用球杆击球,你会将球击向挥杆的方向。
我们在没有明确指示的情况下学习大部分这些东西,纯粹是通过观察和在世界上行动。 我们在生命的最初几个月开发了一个“世界模型”,并了解重力、尺寸、物理特性、因果关系等。 这个模型帮助我们培养常识,并对我们周围的世界将会发生什么做出可靠的预测。 然后,我们使用这些基本构建块来积累更复杂的知识。
当前的人工智能系统缺少这种常识性知识,这就是为什么它们需要大量数据,需要标记示例,并且对分布外的数据非常严格和敏感。
LeCun 正在探索的问题是,我们如何让机器主要通过观察来学习世界模型,并积累婴儿仅通过观察积累的大量知识?
自监督学习
LeCun 认为,深度学习和 人工神经网络 将在人工智能的未来发挥重要作用。 更具体地说,他提倡自我监督学习,这是 ML 的一个分支,可减少对人工输入和神经网络训练指导的需求。
ML 更流行的分支是监督学习,其中模型在标记示例上进行训练。 虽然监督学习在各种应用中都非常成功,但它对外部参与者(主要是人类)进行注释的要求已被证明是一个瓶颈。 首先,有监督的 ML 模型需要大量的人力来标记训练示例。 其次,有监督的 ML 模型无法自我改进,因为它们需要外部帮助来注释新的训练示例。
相比之下,自我监督的 ML 模型通过观察世界、辨别模式、做出预测(有时还采取行动和进行干预)以及根据他们的预测如何匹配他们在世界上看到的结果来更新他们的知识。 它就像一个监督学习系统,自己做数据注释。
自我监督学习范式更适应人类和动物的学习方式。 我们人类进行了很多监督学习,但我们通过自我监督学习获得了大部分基本和常识技能。
自我监督学习是 ML 社区中一个非常受欢迎的目标,因为存在的数据中只有很小一部分被注释了。 能够在大量未标记数据上训练 ML 模型有很多应用。
近年来,自我监督学习已进入 ML 的多个领域,包括大型语言模型。 基本上,自我监督语言模型是通过提供已删除某些单词的文本摘录来训练的。 模型必须尝试预测缺失的部分。 由于原始文本包含缺失部分,因此此过程不需要手动标记,并且可以扩展到非常大的文本语料库,例如 Wikipedia 和新闻网站。 训练后的模型将学习文本结构的可靠表示。 它可用于文本生成等任务,也可用于对问答等下游任务进行微调。
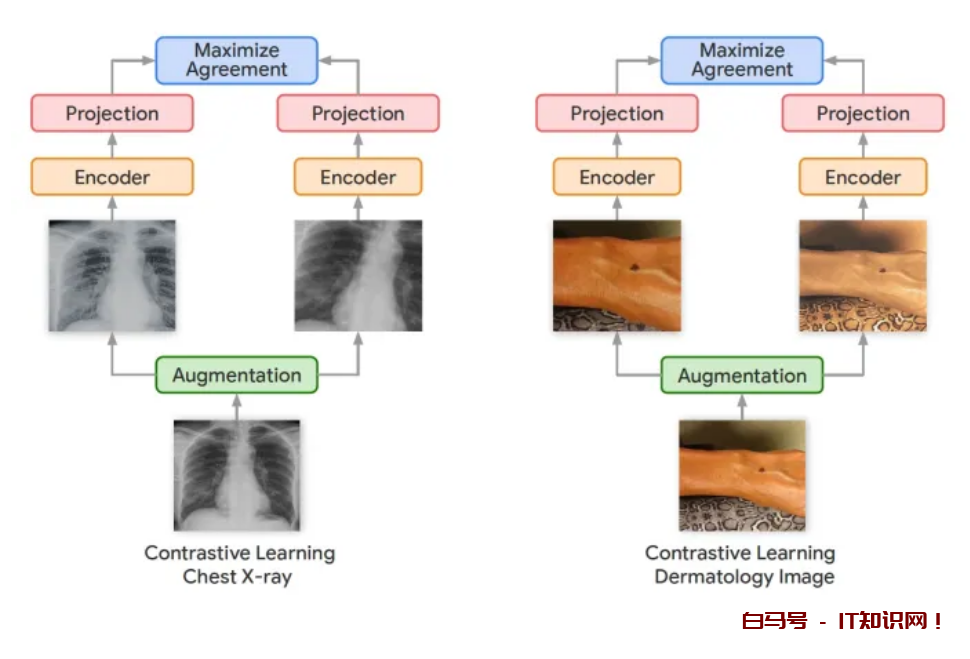
科学家们还设法将自我监督学习应用于医学成像等计算机视觉任务。 在这种情况下,该技术称为“对比学习”,其中训练神经网络以创建未标记图像的潜在表示。 例如,在训练期间,向模型提供具有不同修改(例如,旋转、裁剪、缩放、颜色修改、同一对象的不同角度)的图像的不同副本。 网络调整其参数,直到其输出在同一图像的不同变化中保持一致。 然后可以在带有较少标记图像的下游任务上对模型进行微调。
高级抽象
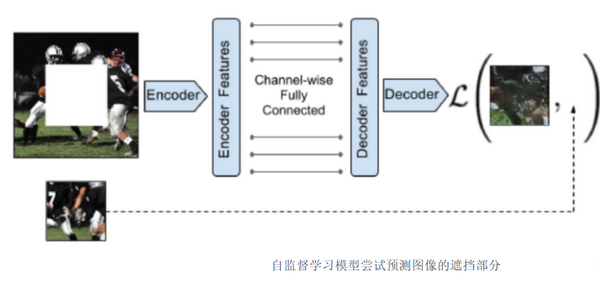
最近,科学家们在计算机视觉任务上尝试了纯粹的自我监督学习。 在这种情况下,模型必须预测图像的被遮挡部分或 视频 。
这是一个极其困难的问题,LeCun 说。 图像是非常高维的空间。 有近乎无限的方式可以在图像中排列像素。 人类和动物擅长预测周围世界发生的事情,但他们不需要在像素级别预测世界。 我们使用高级抽象和背景知识来直观地过滤解决方案空间并关注一些可能的结果。
例如,当您看到一个飞球的视频时,您希望它在接下来的帧中保持其轨迹。 如果它前面有一堵墙,你希望它会反弹回来。 你知道这一点是因为你有直觉物理学的知识,你知道刚体和软体是如何工作的。
同样,当一个人与您交谈时,您希望他们的面部特征会随着帧的变化而变化。 他们说话时嘴巴、眼睛和眉毛会移动,他们可能会稍微倾斜或点头。 但你不要指望他们的嘴巴和耳朵会突然互换位置。 这是因为您的脑海中有面部的高级表示,并且知道支配人体的约束。
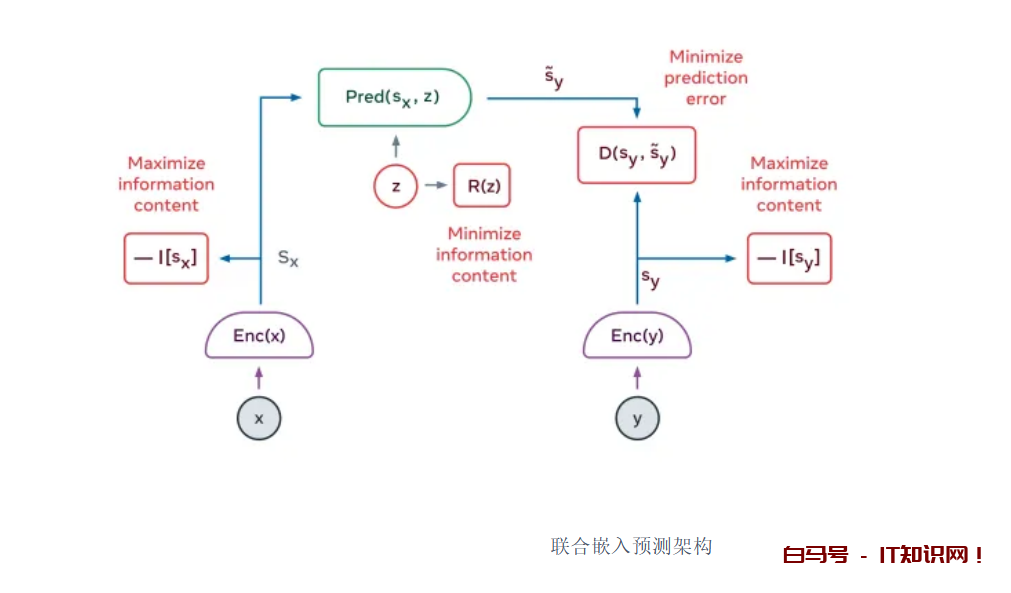
LeCun 认为,具有这些类型的高级抽象的自我监督学习将是开发人类人工智能所需的那种强大的世界模型的关键。 LeCun 正在研究的解决方案的重要元素之一是联合嵌入预测架构 (JEPA)。 JEPA 模型学习捕获两个数据点之间依赖关系的高级表示,例如两个相互跟随的视频片段。 JEPA 用“正则化”技术代替对比学习,这些技术可以从输入中提取高级潜在特征并丢弃不相关的信息。 这使得模型可以对视觉数据等高维信息进行推断。
JEPA 模块可以相互堆叠,以在不同的空间和时间尺度上进行预测和决策。
模块化架构
在 Meta AI 活动上,LeCun 还谈到了人类级别 AI 的模块化架构。 世界模型将是该架构的关键组成部分。 但它也需要与其他模块协调。 其中有一个感知模块,用于接收和处理来自世界的感官信息。 演员模块将感知和预测转化为行动。 短期记忆模块跟踪动作和感知并填补模型信息中的空白。 成本模块有助于评估行动的内在(或硬连线)成本以及未来状态的特定任务价值。
还有一个配置器模块,可以根据 AI 系统想要执行的特定任务调整所有其他模块。 配置器非常重要,因为它在与其当前任务和目标相关的信息上调节模型的有限注意力和计算资源。 例如,如果您正在打或观看篮球比赛,您的感知系统将专注于世界的特定特征和组成部分(例如,球、球员、场地限制等)。 因此,您的世界模型将尝试预测与手头任务更相关的分层特征(例如,球将落在哪里,将球传给谁,持球的球员会投篮还是运球?)和丢弃不相关的特征(例如,观众的动作、篮球场外物体的运动和声音)。
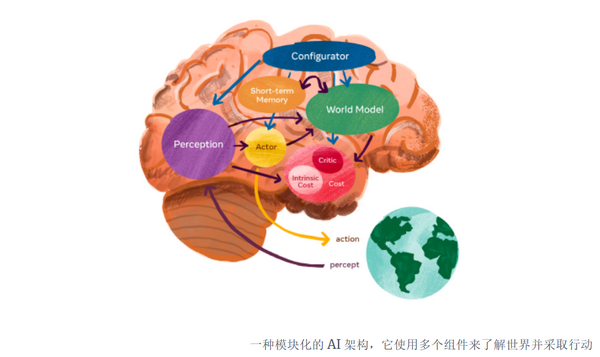
LeCun 认为,这些模块中的每一个都可以以可区分的方式学习它们的任务,并通过高级抽象相互通信。 这与人和动物的大脑大致相似,具有模块化结构(不同的皮层区域、下丘脑、基底神经节、杏仁核、脑干、海马等),每个都与他人和自己的神经结构有联系,随着有机体的经验逐渐更新。
人类级别的人工智能会做什么?
大多数关于人类人工智能的讨论都是关于取代自然智能并执行人类可以完成的每一项任务的机器。 自然,这些讨论会引出诸如技术失业、奇点、失控的智能和机器人入侵等话题。 科学家们对通用人工智能的前景存在广泛分歧。 会不会有人工智能这样的东西,不需要生存和繁殖,这是自然智能进化的主要驱动力? 意识是 AGI 的先决条件吗? AGI 会有自己的目标和愿望吗? 我们可以在没有物理外壳的情况下在大桶中创造大脑吗? 随着科学家们朝着思考机器这一长期追求的目标缓慢前进,这些是一些尚未得到解答的哲学问题。
但更实际的研究方向是创造“与人类智能兼容”的人工智能。 我认为,这就是 LeCun 研究领域的承诺。 这种人工智能可能无法独立做出下一个伟大发明或写出引人入胜的小说,但它肯定会帮助人类变得更有创造力和生产力,并找到解决复杂问题的方法。 它可能会让我们的道路更安全,我们的医疗保健系统更高效,我们的天气预报技术更稳定,我们的搜索结果更相关,我们的机器人不那么愚蠢,我们的虚拟助手更有用。
事实上,当被问及未来人类人工智能最令人兴奋的方面时,LeCun 说他认为这是“人类智能的放大,每个人都可以做更多的事情,更有效率,更有创造力,花费更多更多的时间去完成活动,这是技术进化的历史。”
Ben Dickson 是一名软件工程师,也是 TechTalks 的创始人。 他撰写有关技术、商业的文章。
声明:所有白马号原创内容,未经允许禁止任何网站及个人转载、采集等一切非法引用。本站已启用原创保护,有法律保护作用,否则白马号保留一切追究的权利。发布者:白马号,转转请注明出处:https://www.bmhysw.com/article/9102.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 